Are you ignoring the cockpit and the engine?
Complex data pipelines can lead to the introduction of systemic biases in research data. Qudol helps to reduce these biases by algorithmically linking data from any source with unlimited history.
Vale Sundaravel
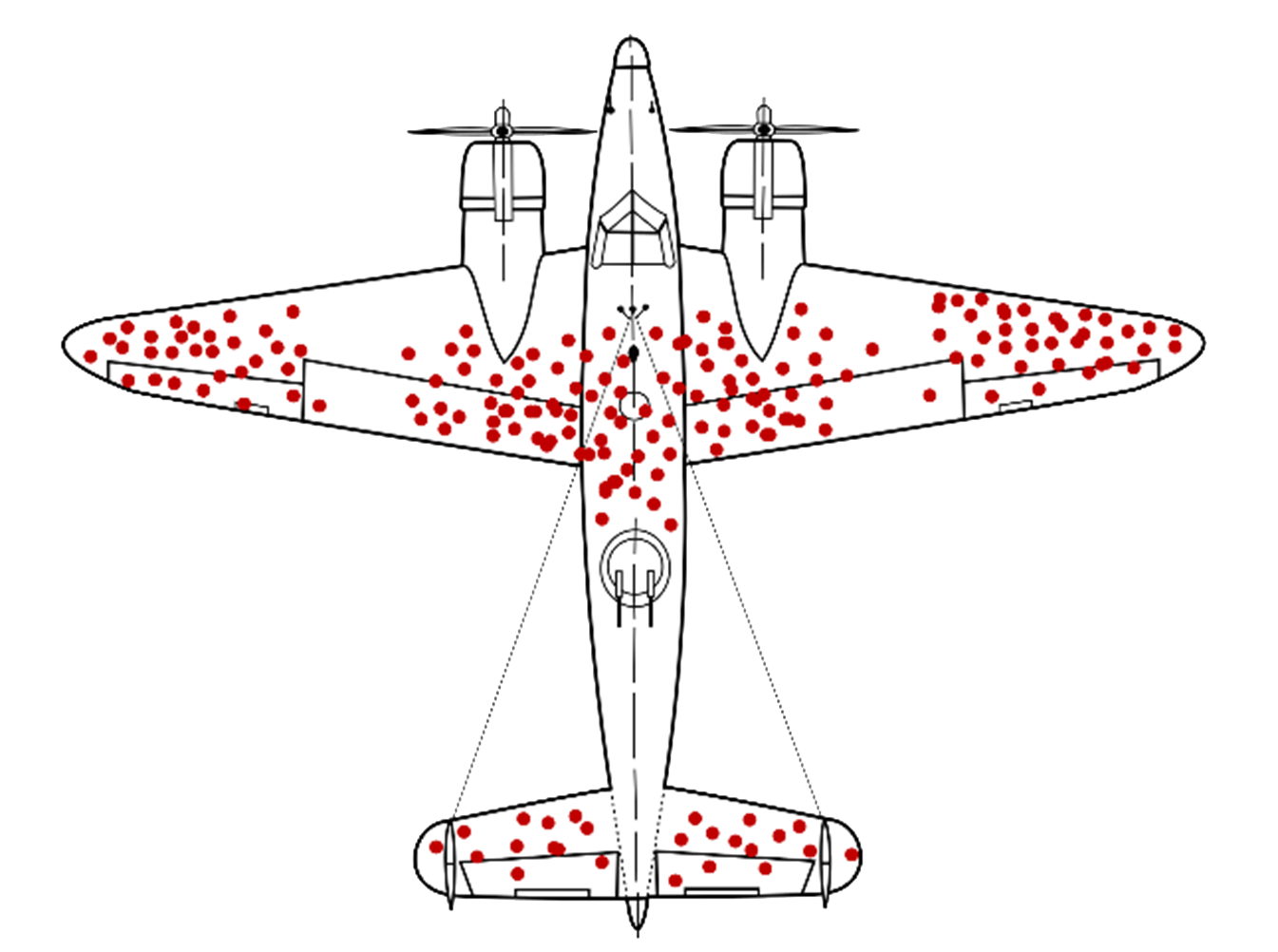
Source: Wikipedia.
First, a history lesson:
One of the most well-known examples of data bias is shown above: the red dots represent a mapping of bullet holes in World War II aircraft. Abraham Wald from Columbia University's Statistical Research Group famously concluded that the density of bullet holes was inversely correlated with a need for more armor plating, recognizing that aircraft struck in the other areas - the cockpit and the engine - simply didn’t make it back home.
This is a case of survivorship bias, where failures are not taken into consideration when examining a dataset. Typically, biases such as these can lead to unintentionally non-representative, over-correlated and overly optimistic conclusions. Moreover, we’ve seen in practice that these issues often arise from the complexity of the data pipeline – the consequence of having multiple data sources from multiple data vendors with multiple sets of nonconforming unique identifiers.
Running out of time to read this article? Here are the key takeaways:
|
|
Qudol uses deep history to tackle data complexities.
In our World War II example, the solution was to turn to the statistical experts. In modern day financial services data analysis, Qudol tackles issues of bias by creating a one-to-one cross-reference across all sources, selecting the best match at any point in time using consistent rules. With no limits on depth of history, Qudol provides researchers with the most comprehensive view of any security over time.
By algorithmically and automatically linking data across all sources and history, Qudol efficiently reduces risk of systematic data bias.
Let me show you an example of Qudol in action by highlighting the impact of a single index change.
Case Study: Teva Pharmaceutical
Teva is a pharmaceutical company that was founded in Israel in 1901, and listed on the Tel Aviv Stock Exchange in 1951. Teva was also listed on the NYSE as an ADR, meaning that the exact same company had two different identities in the data.
Teva's listing on the Tel Aviv Stock Exchange had limited liquidity and little trading. In 2016, MSCI replaced TEVA.TA (Tel Aviv) with TEVA (ADR/US) in the index for liquidity reasons (link to announcement).
This change to the MSCI dataset has the following implications for research and analysis:
- Fragmentation of TEVA Records: The rows corresponding to the two versions of Teva are not connected inside MSCI. If an analyst looks at what is happening within the index, she will only see the newer TEVA (ADR/US), and not the previous TEVA.TA that was dropped because of liquidity issues. This introduces survivorship bias.
- Loss of History: Looking at TEVA within the index, there are records going back to 2016. However, there's actually history going back to 1982 across multiple other data sources. The lack of linkages across history and across data sources introduces exclusion bias.
These data inconsistencies, and the resulting biases in downstream analysis, are algorithmically tackled by Qudol through its deep-linking using its unique time-series linking identifier, QUID.
| QUID* | AssetCode* | FromDate | Name | Trading Symbol |
|---|---|---|---|---|
| USA5555123 | MSCIG-01234551 | 1996-12-31 | TEVA PHARMACEUTICAL IND | TEVA.TA |
| USA5555123 | MSCIG-01234562 | 2016-11-01 | TEVA PHARMA IND ADR | TEVA |
* Identifiers have been obfuscated for compliance. Names and dates may be fictitious, but meaningful.
In the simplified table above, there are two unique rows in the MSCI dataset without any inherent linkages between them. The "new TEVA" appears with a brand new asset code, as if it's an entirely new asset. Even the time series code (tsCode) changes. However, both of them have relevant and overlapping history, with the ADR going back to 1982 and TEVA.TA going back to 1994.
Qudol correctly assigns QUIDs to all variants, even with different SEDOL and CUSIP identifiers. The MSCI data does provides a hint in that the issuers are the same, but this is neither a definitive linkage (they could simply be different share classes), nor would this type of disambiguation be automatic or scalable. In this example, Qudol can connect these MSCI assets by cross-referencing BARRA data using the root ID.
The bottom line is that Qudol automatically resolves these issues within your dataset, for TEVA and countless other instances of corporate actions, benchmark changes, and other critical data events across time.
So what? The impact of missing or incorrect linkages
Systematic data biases start in the underlying data and data preparation, and end in unintended model outcomes. The impact of missing or incorrect data linkages is challenging to quantify, but even in very simple data structures, has been shown to lead to 2-3x increase in error rates.
Qudol’s algorithm has built in validation, meaning that it actively searches for and identifies linkage issues. When possible, Qudol uses its configurable waterfall hierarchy to refine and deliver clean, current data. Additionally, we recognize that a (small) subset of scenarios always requires expert disambiguation; Qudol automatically identifies these anomalies and alerts your team. My colleague Matt covers these items in his post on Accuracy and Validation.
If you have any questions or are interested in learning more, please connect with us. We look forward to discussing your thorniest financial data challenges!
Vale Sundaravel
Founder & President